
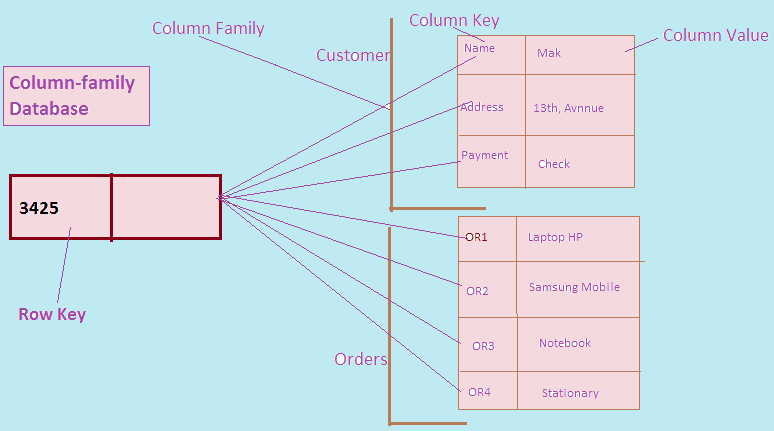
NoSQL column family database is another aggregate oriented database. In NoSQL column family database we have a single key which is also known as row key and within that, we can store multiple column families where each column family is a combination of columns that fit together.
Column family as a whole is effectively your aggregate. We use row key and column family name to address a column family.
It is, however, one of the most complicated aggregate databases but the gain we have in terms of retrieval time of aggregate rows. When we are taking these aggregates into the memory, instead of spreading across a lot of individual records we store the whole thing in one database in one go.
The database is designed in such a way that it clearly knows what the aggregate boundaries are. This is very useful when we run this database on the cluster.
As we know that aggregate binds the data together, hence different aggregates are spread across different nodes in the cluster.
Therefore, if somebody wants to retrieve the data, say about a particular order, then you need to go to one node in the cluster instead of shooting on all other nodes to pick up different rows and aggregate it.
Among the most popular column family NoSQL databases are Apache HBase and Cassandra.
Aggregate orientation is not always a good thing.
Let us consider the user needs the revenue details by product. He does not care about the revenue by orders.
Effectively he wants to change the aggregate structure from order aggregate line item to produce aggregate line items. Therefore, the product becomes the root of the aggregate.
In a relational database, it is straightforward. We just query few tables and make joins and the result is there on your screen. But when it comes to aggregate orientation database it is a pain.
We have to run different MapReduce jobs to rearrange your data into different aggregate forms and keep doing the incremental update on aggregated data in order to serve your business requirement, but this is very complicated.
Therefore, the aggregate oriented database has an advantage if most of the time you use the same aggregate to push data back and forth into the system. It is a disadvantage if you want to slice and dice data in different ways.
Application of Column family NoSQL Database
Let us understand the key application of column family NoSQL database in real world scenarios.
Big Table (Column Family Database) to store sparse data
We know that NULL values in the relational database typically consume 2 bytes of space.
This is a significant amount of wasted space when there are a number of NULL values in the database.
Let us suppose we have a “Contact Application” that stores username and contact details for every type of the network such as Home-Phone, Cell-Phone, Zynga etc.
If let us say for few of the user only Cell-Phone detail is available then there will be hundreds of bytes wasted per record.
Below is the sample contact table in RDBMS which clearly depicts the waste of space per record.
| ContactID | Home-Phone | Cell-Phone | Email1 | Email2 | ||
| 1X2B | NULL | 9867 | x@abc | NULL | NULL | NULL |
| 2X2B | 1234 | NULL | NULL | NULL | NULL | #bigtable |
| 3X3Y | 3456 | 9845 | NULL | y@wqa | a@fb.com | #hadoop |
| Contact Table in RDBMS | ||||||
The storage issue can be fixed by using the BigTable which manages sparse data very well instead of RDBMS.
The BigTable will store only the columns that have values for each record instance.
If we indicate only Home-Phone, Cell-Phone and Email1 details that need to be stored for ContactID ‘1X2B’ then it will store only these three column values and rest will be ignored i.e. null will not be considered and hence no wastage of space.
| RowKey | Column Values | |
| 1234 | ph:cell=9867 | email:1=x@abc |
| 3678 | social:twitter=#bigtable | ph:home=1234 |
| 5987 | email:2=y@wqa | social:facebook=a@fb.com |
| Contact Table in Big Table Storage | ||
Analysing Log File using BigTable
Log analysis is a common use case for any Big Data project. All data generated through log files by your IT infrastructure often are referred to as data exhaust.
The vast information about the logs is stored in big tables. It is then analyzed nearly in real time in order to track the most updated information.
The reason why log files are stored in the BigTable is that they have flexible columns with varying structures.
| HostName | IP Address | Event DT | Type | Duration | Description |
| server1 | 10.219.12.3 | 4-Feb-15 1:04:21 PM | dwn.exe | 15 | Desktop Manager |
| server2 | 10.112.3.45 | 4-May-15 1:04:21 PM | jboss | 45 | |
| Typical Log File | |||||
| RowKey | Column Values | |||||
| 12AE23 | host:name=server1 | ip:address =10.219.12.3 | event:DT=4-Feb-15 1:04:21 PM | Type= dwn.exe | Dur=15 | Desc= Desktop Manager |
| Log File stored in BigTable | ||||||