
In this post, we will discuss Hive data types and file formats.
Hive Data Types
Hive supports most of the primitive data types that we find in relational databases. It also supports three collection data types that are rarely supported by relational databases.
Hive Primitive data types
| Type | Size | Literal Syntax Example |
| TINYINT | 1-byte signed integer, from -128 to 127 | 30 |
| SMALLINT | 2-byte signed integer, from -32,768 to 32,767 | 30 |
| INT | 4-byte signed integer | 30 |
| BIGINT | 8-byte signed integer | 30 |
| FLOAT | 4-byte single precision floating point number | 8.16 |
| DOUBLE | 8-byte double precision floating point number | 8.16 |
| BOOLEAN | Boolean Ture or False | TRUE |
| TIMESTAMP | Only available starting with Hive 0.8.0 | 2016-02-02 11:41:56′ |
| DATE | DATE values describe a particular year/month/day, in the form YYYY-MM-DD | ‘2013-01-01’ |
| STRING | Sequence of characters with either single quotes (‘) or double quotes (“) | ‘Learn HIVE’ |
| VARCHAR | Varchar types are created with a length specifier (between 1 and 65355) | ‘Learn HIVE’ |
| CHAR | Char types are similar to Varchar but they are fixed-length | ‘Learn HIVE’ |
| BINARY | Array of Bytes | 11101 |
Hive Collection Data Types
| Type | Expression | Literal Syntax Example |
| ARRAY | It is the collection of similar type of elements that are indexed. It is similar to arrays in Java. | array(‘mak’,’mani’);The second element is accessed with array[1] |
| MAP | Collection of key, value pair where fields are accessed by array notation of keys. | MAP(‘first’,’Kumar’,’last’,’Mak’).’first’ and ‘last’ is the column name in the table and ‘Kumar’ and ‘Mak’ are the values. The last name can be referenced using name[‘last’] |
| STRUCT | It is similar to STRUCT in C language where fields can be accessed using “dot” notation. | For a column c of type STRUCT {a INT; b INT} the a field is accessed by the expression c.a |
Below table structure demonstrates the Hive data types and their uses.
CREATE TABLE EMP ( Ename STRING, EmpID INT, Salary FLOAT, Tax MAP<STRING, FLOAT>, Subordinates ARRAY<STRING>, Address STRUCT<city: STRING, state: STRING, zip: INT> )
The ename column is a simple string which is the name of each employee, EmpID is the number assigned to each employee to uniquely identify the employee working for an organization and float is for employee’s salary.
Tax column is a map that holds the key-value pair for every deduction that will be taken out from employee’s salary.
For example, Tax can be (“professional tax”) where value can be a percentage value or an absolute number. In traditional databases, there might be a separate table which will be holding the Tax type and the corresponding values.
Data examples of the above create table statement can be a JSON (JavaScript Object Notation) file with below data:
{
“Ename”: “Kumar Mak”,
“EmpID”: 1234,
“Salary”: 5000.0,
“Tax”: {
“Professional Tax”: .3,
“State Tax”:05
“Fedral Tax”:.1
},
“Subordinates”: [“Smith”, ”John”, ”Carley”],
“Address”: {
“city”: “London”,
“State”: “UK”
“Zip”:560076
}
}
A file format is a way in which information is stored in a computer file. Below is the default delimiters table for the fields:
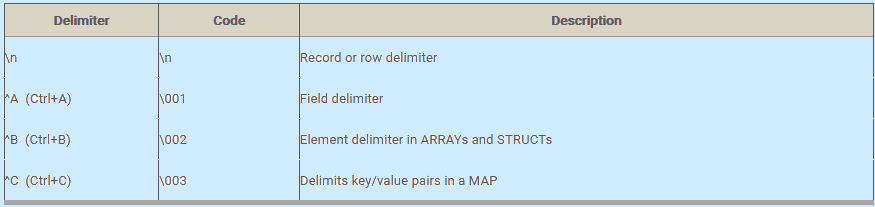
Below is the same “EMP” table with the format specified:
CREATE TABLE EMP ( Ename STRING, EmpID INT, Salary FLOAT, Tax MAP<STRING, FLOAT>, Subordinates ARRAY<STRING>, Address STRUCT<city: STRING, state: STRING, zip: INT> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' COLLECTION ITEMS TERMINATED BY '\002' MAP KEYS TERMINATED BY '\003' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
The “ROW FORMAT DELIMITED” keyword must be specified before any other clause, with an exception of the “STORED AS” clause.
It specifies the format of data rows. ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\001’ meaning that HIVE will use “^A” character to separate fields. ‘\001’ is the octal code for “^A”. Similarly, ‘\002’ is the octal code for “^B” and so on.
“STORED AS” specifies the type of file in which data is to be stored. The file can be a TEXTFILE, SEQUENCEFILE, RCFILE, or BINARY SEQUENCEFILE.
Schema on Read
When we write data into traditional databases either by INSERT, UPDATE operation or through loading external data etc. The database has control on its storage. It can enforce schema as the data is written. This is called schema on write.
Hive has no control over the underlying storage. There are many ways to create, update or delete the data from the HDFS storage through the Hive Query. Therefore,
Therefore, Hive can only enforce queries on read. Hence, this is called as schema on read.