
Hadoop Distributed File System (HDFS) is a file system that provides reliable data storage for large data-set in distributed computing environment using cluster of commodity servers.
When the data enters into HDFS file system, it breaks down into smaller chunks default 64 MB chunk and then gets distributed across the different nodes in the cluster allowing it for parallel processing.
The file system also copies each 64 MB chunk to multiple machines depending on the replication factor mentioned in HDFS configuration file.
This allows HDFS to be fault tolerance. An example of HDFS file system would be phone number of everyone across the globe stored in a file.
Our goal is to get the number of people whose first name starts with “A”. As soon as the file will arrive at HDFS file system it will break into default 64 MB chunk scattered across the commodity servers.
To reconstruct the cluster in order to achieve the output as count file, we have to write a program which will go to each node in the cluster and get the aggregated count information which will finally be summed up to get the final output.
To achieve availability of each node where 64 MB chunk is residing, HDFS replicates these 64 MB chunks onto two additional servers by default.
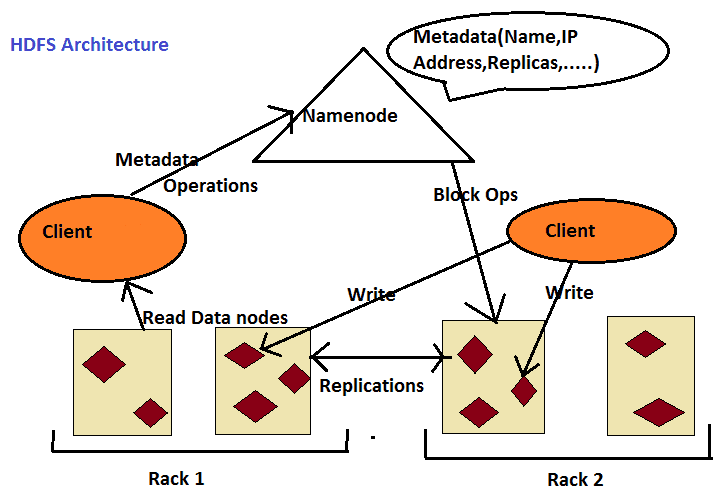
HDFS file system has master-slave architecture. Master is called as Name node. Name Node is a high-end server.
Along with master we have one more high-end server which is called secondary name node.
All other servers are normal machines i.e. 2 GB/4GB RAM machines which we call it as commodity machines or slave machines.
Data blocks which by default is 64 MB chunk resides on commodity machines or slave machines. It is important to understand that secondary name node is not a backup machine.
The pertinent question here is what name node and secondary name node does.
Name node keeps the metadata information about the data blocks residing on commodity machines or slave machines in Hadoop cluster.
Only the name node in the whole Hadoop eco system has the information about which data blocks resides on what commodity machine.
Name node basically has the name and path of the data blocks along with the IP address of commodity machine where data blocks reside.
File system operations such as opening, closing, renaming files and directories are executed by name node.
The Data Nodes are responsible for serving read and write requests from the file system’s clients. The Data Nodes also perform block creation, deletion, and replication upon instruction from the name node.
It is the job of Data Nodes for serving read and writes requests from the clients file system.
Data Nodes also performs data block creation, deletion, and replication upon instruction from the Name Node in order to have fault-tolerance capabilities.
Any machine that supports JAVA can run Name Node and Data Node software since HDFS is built using open source JAVA programming language.
Name Node has background process running. Metadata of all the changes which are happening to data blocks such as block creation, deletion are stored in Edit logs of name node.
Edit log is basically one of the construct of name node where filesystem metadata is stored.
Another construct of name node is fsimage that keeps point-in-time snapshot of the file system metadata.
Once the name node is restarted, edit logs are applied to fsimage to get the most recent snapshot of the HDFS. But the name node restarts are very rare in Hadoop eco-system and hence edit log will grow very huge over a period of time. The challenges at this point of time would be as below:
- Edit log size will grow over a period of time, which will be difficult to manage.
- Restart of name node will take time since huge changes need to be merged from edit log to fsimage.
- In case of any fault, we will lose huge amount of metadata.
Secondary Name Node helps to overcome the above issue by taking over responsibility of merging editlogs with fsimage from the name node.
Secondary name node gets the edit logs from name node in a regular interval and applies to the fsimage of itself i.e. secondary name node.
Once secondary name node has the new fsimage, it copies fsimage back to namenode. In this way name node will always have the most recent information about the metadata.
This is why we do not call secondary name node as replacement or backup for the name node. It is also named as checkpoint node for the above reason.
Summary of sequence of steps which takes place when the HDFS cluster starts:
- Start the cluster for first time.
- Name Node receives the heartbeat from all commodity servers.
- All the commodity servers regularly pings the name node. This ping is called heartbeat. In the heartbeat it sends the information about which block is residing on what commodity server.
- Using the above information, name node creates a file which we call it as “fsimage”.
- Till the time “fsimage” is created, name node is locked up. Once the creation process completes, it passes the information to Secondary name node and unlock itself.
- If creation/deletion of data blocks takes place at different data nodes, Name node writes the updated metadata information to edit logs.
- It passes the edit logs information to Secondary namenode. Edit logs information will get applied to Secondary name node fsimage i.e. the delta changes will be captured in edit log of name node and further passed to Secondary name node. Secondary name node will take this delta changes and create a new fsimage using the edit log of name node.
- Secondary name node passes the most recent fsimage back to name node. Hence, name node will always have the most recent information about the metadata.